ぷららのblogサービス「Broach」のあまりの重さと対応の遅さに業を煮やし、工房blogを移設した訳ですが、
これまでにも、多くの利用者の皆さんから、「登録記事のバックアップ機能(エクスポート機能)」の追加要望が出されていますが、Broachスタッフ側は、いっこうに動いている気配が見えません。要望に応えるつもりは、まったく無いようです。
(私の記憶が確かならば、かなり以前に「今後の追加機能(予定)」として書かれていたように思いますが、いまでは跡形もなく消されています)
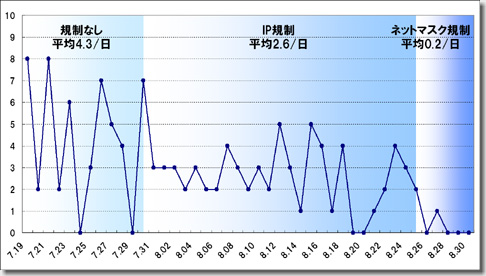
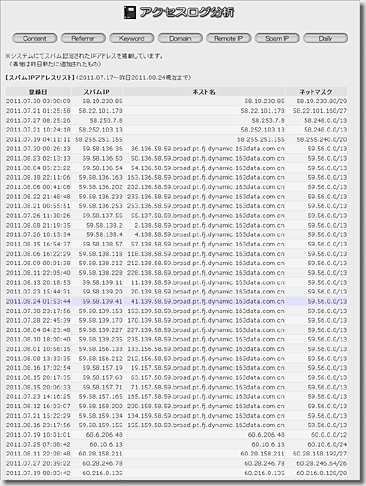
#まぁ、これだけグダグダな管理運営体制なので、エクスポート機能をリリースした途端、多くの利用者が他社に流出してしまうので、そんなリスクは冒せないのだと思いますが。0xF9D1
工房blogを移設するまでにBroachに登録した記事は、700エントリを越えています。
これまでしこしことマニュアルで移植していたのですが、半年以上経った現在、まだ100エントリほどしか完了していません。
遅々として進まないのは、BroachからMT(Movable Type)へ移植するにあたっては、いろいろと越えなければならないステップ(後述)があり、これに手間取っていたためです。
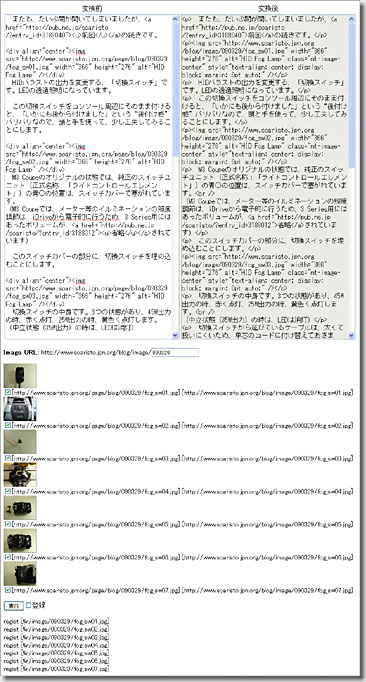
「やらぬなら、作ってしまえ、エクスポート機能」ということで、PHPのスクリプトをゴリゴリ書いて、作ってしまいました。0xF9F8
若干マニュアルなところが残っていますが、ほぼオートマティックに移植することができます。
動作としては、左側の枠にBroachの記事(HTML)をコピー&ペーストし、実行ボタンを押すと、XHTML Validなものに整形・変換してくれます。
同時に、HTMLの中からBroachにアップロードしたアイテム(画像など)を抽出し、MTのアイテムとして自動的に登録してくれます。
その際、Broachでは、アイテムの名称(ファイル名)を勝手にシリアルなものに変換してしまいますが、Broachにアップロードした時のオリジナルの名称に戻してから、MTに登録してくれます。
(以下、詳細略)
いや~、ぷららさんのお陰で、PHPによるSQLサーバ連携のよい勉強ができました。(もちろん、アイロニーな意味ですけど)0xF9D1
これで、BroachからMTへの移植が進むかと思います。最終的には、Broachを解約します。
| 21 Related Entries | |
【SEO対策】403/404エラーを解析する | Next ATOK 2012 for Windows |
 SOARISTO at 10:40:42
|
Comment(0)
|
Trackback(0)
SOARISTO at 10:40:42
|
Comment(0)
|
Trackback(0)Link URL: https://www.soaristo.org/blog/archives/2011/11/111120.php