前回のフォローです。
中国、韓国、その他からのアクセスを、“片っ端から遮断して”気を良くしていたところ、特定のIPアドレス空間からのアクセスが、遮断できていないことが分かりました。
以前にも出てきた、
*.dynamic.163data.com.cn
からのものです。
ダダ漏れでした。0xF9FC
結論からいうと、IPアドレス空間から、CIDRを求める関数に問題がありました。
前回は、IPの開始アドレスと終了アドレスから、ちょ~イイ加減な方法でCIDRを算出していました。また、PHPのオンラインマニュアルにある例題の関数「ip2cidr()」にも、問題があることか分かりました。
いろいろ試行錯誤して分かったことは、「Whoisコマンドを使ってAPNICから得られるIPアドレス空間には、複数のCIDRブロックで構成されているものがある」ということでした。
ということで、さっそく改修です。
上記は、PHPスクリプトの例です。
冒頭の“ダダ漏れリスト”の「218.86.48.48」について、APNICにてIPアドレス空間(inetnum)を求めると、「218.85.0.0 - 218.86.127.255」と出てきます。
これを、上記の関数(1)「ちょ~イイ加減な方法」と、関数(2)「PHPのオンラインマニュアルにある例題」に掛けると、CIDRは、「218.85.0.0/15」と出てきます。
32-15=12bit分のアドレス空間が遮断されるので、一見、合ってそうに思えますが、これでは「218.86.*.*」のアドレス空間が、遮断されていないことになります。
218.85.0.0/16
218.86.0.0/17
正しくは、上記の2つのCIDRブロックを遮断しなければなりません。
ということで、IPアドレス空間から、CIDRを求める正しい関数が、関数(3)「range2cidrlist()」です。
基本的には、PHPのオンラインマニュアルにある例題の関数と同じですが、微妙に修正してあります。(ネットマスクが32だった場合に、正しく計算されないバグを修正)
この関数は、IPアドレスの範囲(開始アドレスと終了アドレス)を与えると、その範囲に含まれるCIDRブロックを、リスト(配列)として返します。
#正しく計算されているかどうかは、ここなどを参照。
この返り値を元に、スパムテーブルと.htaccessとを更新し、なんとか“漏れ”を止めることができました。
ふ~っ、めでたし、めでたし。0xF9C6
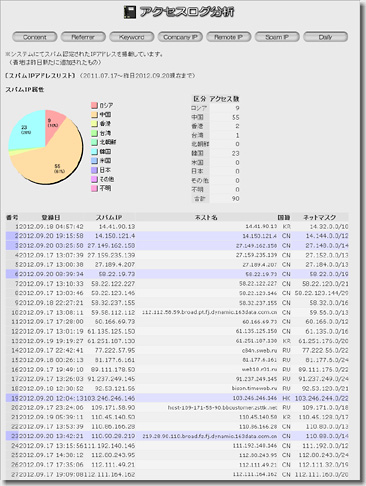
それにしても、相変わらず中国からのアクセスが多いです。全体の3分の2近くを占めています。
引き続き、片っ端から遮断していくことにします。0xF9D1
| 21 Related Entries | |
 【セキュリティ対策】特定の国からのアクセスを遮断する | Next 【MT5】SQLのナンバリングを調節する(コメント編) |
 SOARISTO at 20:16:38
|
Comment(0)
|
Trackback(0)
SOARISTO at 20:16:38
|
Comment(0)
|
Trackback(0)Link URL: https://www.soaristo.org/blog/archives/2012/09/120920.php